ModeShape is an open source implementation of the JSR-283 specification and standard JCR API. This tutorial will provide a basic introduction to the ModeShape framework and the JCR specification.
Warning Project no longer maintained!
Unfortunately, this project is no longer receiving updates. The last release for ModeShape 5.4.1 dates back to April 19, 2017. We recommend checking other alternatives such as JackRabbit Oak. You can check this JackRabbit Oak tutorial to get started.
Content Repository API for Java (JCR) is a specification for a Java platform application programming interface (API) to access content repositories in a uniform manner. A JCR is a type of object database which can be used for storing, searching, and retrieving hierarchical data.
At first sight you might wonder what’s the advantage of using JCR against a database (for example, also a traditional RDBMS is able to store documents as binary data) . A JCR repository is quite different from a RDBMS because it exibits the following features:
- It Is hierarchical, allowing your to organize your content in a structure that closely matches your needs and where related information is often stored close together and thus easily navigated
- It’s flexible, allowing the content to adapt and evolve, using a node type system that can be completely “schemaless” to full-on restrictive (e.g., like a relational database)
- Uses a standard Java API (e.g., javax.jcr)
- Abstracts where the information is really stored: many JCR implementations can store content in a variety of relational databases and other stores, some can expose non-JCR stores through the JCR API, and some can federate multiple stores into a single, virtual repository.
- Supports queries and full-text search out of the box
- Supports events, locking, versioning, and other features
What kind of applications can benefit from these features? The JCR API initially grew out of the needs of Content Management Systems, which require storing documents and other binary objects with associated metadata; however, the API is now applicable to many other type of applications which require for example versioning of data; transactions; observation of changes in data; and import or export of data to XML in a standard way.
Introducing ModeShape
Modeshape is an opensource implementation of the JCR 2.0 API and thus behaves like a regular JCR repository. Applications can search, query, navigate, change, version, listen for changes, etc. ModeShape can store that content in a variety of back-end stores (including relational databases, Infinispan data grids, JBoss Cache, etc.), or it can access and update existing content from *other* kinds of systems (including file systems, SVN repositories, JDBC database metadata, and other JCR repositories).
How’s data organized into Modeshape ? data is organized into a tree structure that reflects the way data is accessed or used. As you can see from the following picture, in many scenarios there is a natural hierarchy between records which can be navigated using queries.
Each JCR node contains the following elements:
- Name path and identifier
- Properties (name and values)
- Child nodes
- One or more Node Type
The Node Type element, in particular, defines the allowed properties in the node (name/value/searchable/mandatory)
define the allowed child nodes
Using ModeShape API
Modeshape has an extensive set of API which can be used to programmatically access, find, update and query content of a Content Repository. It does also include extended JCR interfaces for managing additional node and event types or using sequencers and text SPIs.
In this tutorial we will see a simple basic JSF + CDI application which interacts with a Modeshape repository. Our application will be made up just of two simple JSF views:
- One for inserting Nodes into the Repository
- Another view for displaying a tree view of the repository
Let’s start our journey. The first class we will include is a CDI Producer, which is responsible for creating instances of a JCR Session object:
public class SessionProducer {
@Resource(mappedName = "java:/jcr/sample")
private Repository sampleRepository;
@RequestScoped
@Produces
public Session getSession() throws RepositoryException {
System.out.println("Creating new session...");
return sampleRepository.login();
}
public void logoutSession( @Disposes final Session session ) {
System.out.println("Closing session...");
session.logout();
}
}
The javax.jcr.Session object provides read and write access to the content of a particular workspace in the repository. In our example, the Session is bound to the repository named “sample” that is available under the JNDI tree as “java:/jcr/sample“.
The Session object will be injected into our main CDI Bean, which is in charge to insert new Nodes into the repository:
@Model
public class RepositoryManager {
String node;
String path;
@Inject
private Session jcrSession;
public void add() {
System.out.println("Session established successfully to repository at: "
+ jcrSession.getRepository());
try {
// Returns the node at the specified absolute path in the workspace.
Node rootNode = jcrSession.getNode(path);
// Add a new Node under the path specified by rootNode
rootNode.addNode(node);
// Validates all pending changes currently recorded in this Session.
jcrSession.save();
FacesContext context = FacesContext.getCurrentInstance();
context.addMessage(null, new FacesMessage("Info", "Added Node " + node ));
} catch (Exception e) {
System.out.println("Could not complete request" + e);
}
}
public String getPath() {
return path;
}
public void setPath(String path) {
this.path = path;
}
public String getNode() {
return node;
}
public void setNode(String node) {
this.node = node;
}
}
As you can see from the above commented code, by using CDI Producers it is trivial to access to the JCR Session and manage the Nodes of the repository.
And here is the first view that enables adding data via the RepositoryManager bean:
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:p="http://primefaces.org/ui">
<h:head></h:head>
<h:body>
<p:growl id="growl" showDetail="true" sticky="true" />
<h:form id="form">
<h3>ModeShape 4 Demo</h3>
<h:panelGrid columns="2" cellpadding="5">
<h:outputText value="Path: " />
<p:inputText id="path" value="#{repositoryManager.path}" />
<h:outputText value="Node: " />
<p:inputText id="node" value="#{repositoryManager.node}" />
</h:panelGrid>
<p:commandButton id="add" action="#{repositoryManager.add}"
update=":growl" value="Add" />
<p:commandButton id="display" action="display" value="View" />
<br />
</h:form>
</h:body>
</html>
The above code is pretty simple and includes the PrimeFaces library which is now the de facto standard for JSF applications.
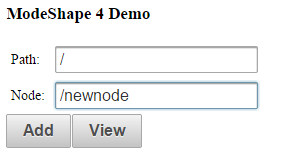
So far we have covered Node insertion. What about having a look at our repository ? the PrimeFaces library has an awesome showcase of components for showing data. I have chosen the org.primefaces.model.TreeNode which reminds me of the good old Swing interfaces. By using the TreeNode with JCR API we can easily create a Bean which produces the content of the Repository tree:
@Model
public class TreeView implements Serializable {
private TreeNode root;
@Inject
private Session jcrSession;
@PostConstruct
public void init() {
root = new DefaultTreeNode("Root", null);
try {
Node rootNode = jcrSession.getRootNode();
root = newNodeWithChildren(rootNode, null);
} catch (Exception e) {
e.printStackTrace();
}
}
public TreeNode newNodeWithChildren(Node jcrNode, TreeNode parent)
throws Exception {
TreeNode newNode = new DefaultTreeNode(jcrNode.getName(), parent);
NodeIterator nodeList = jcrNode.getNodes();
while (nodeList.hasNext()) {
Node tt = (Node) nodeList.next();
TreeNode newNode2 = newNodeWithChildren(tt, newNode);
}
return newNode;
}
public TreeNode getRoot() {
return root;
}
}
The second view, just contains as little as a tree elementm with a reference to our CDI Bean:
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:p="http://primefaces.org/ui">
<h:head></h:head>
<h:body>
<h:form id="form">
<h3 style="margin-top: 0">Repository</h3>
<p:tree value="#{treeView.root}" var="node" orientation="horizontal">
<p:treeNode>
<h:outputText value="#{node}" />
</p:treeNode>
</p:tree>
<h:commandButton id="Home" action="index" value="Home" />
</h:form>
</h:body>
</html>
And here is a view of our Repository which uses a client-based TreeNode:
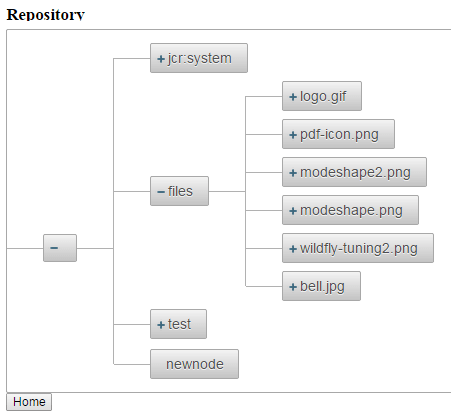
Isn’t it impressing how we can have a view of our JCR Repository with so few lines of code ?
Lastly, here is the pom.xml I have used to compile and deploy the Modeshape web application on WildFly:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.mastertheboss</groupId>
<artifactId>modeshape-webapp</artifactId>
<version>1.0</version>
<packaging>war</packaging>
<name>Basic Modeshape Example</name>
<properties>
<version.modeshape>4.1.0.Final</version.modeshape>
<endorsed.dir>${project.build.directory}/endorsed</endorsed.dir>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<version.jboss.bom>8.0.0.Final</version.jboss.bom>
</properties>
<repositories>
<repository>
<id>JBoss Repository</id>
<url>https://repository.jboss.org/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.wildfly.bom</groupId>
<artifactId>jboss-javaee-7.0-with-all</artifactId>
<version>${version.jboss.bom}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.modeshape.bom</groupId>
<artifactId>modeshape-bom-jbossas</artifactId>
<version>${version.modeshape}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>javax.jcr</groupId>
<artifactId>jcr</artifactId>
</dependency>
<dependency>
<groupId>org.modeshape</groupId>
<artifactId>modeshape-jcr-api</artifactId>
</dependency>
<dependency>
<groupId>org.primefaces</groupId>
<artifactId>primefaces</artifactId>
<version>5.1</version>
</dependency>
<dependency>
<groupId>javax.enterprise</groupId>
<artifactId>cdi-api</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.jboss.spec.javax.faces</groupId>
<artifactId>jboss-jsf-api_2.2_spec</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}</finalName>
<plugins>
<plugin>
<groupId>org.wildfly.plugins</groupId>
<artifactId>wildfly-maven-plugin</artifactId>
<version>1.0.2.Final</version>
</plugin>
</plugins>
</build>
</project>
Since we have included the Maven WildFly plugin, you can deploy your application to WildFly with:
$ mvn clean install wildfly:deploy
Download the source code of the Modeshape 4 in action tutorial.
Found the article helpful? if so please follow us on Socials


